Instagram Scraping in 2025: Why I Recommend BrowserAct over Traditional APIs

Compare Apify’s Instagram Scraper with BrowserAct’s no-code, geo-proxy tool. Learn which option solves blocks, CAPTCHAs, and time-to-data for your use case.
You need Instagram data—maybe for influencer discovery, maybe to track brand sentiment. Yet constant blocks, CAPTCHAs, and IP restrictions turn a simple request into hours of firefighting. Today you’ll learn a workflow that pairs Apify’s Instagram Scraper with BrowserAct’s no-code agent and free regional proxy so you can collect clean, geo-targeted data without headaches.
The Current Landscape & Pain Points
Scraping Instagram data is harder than ever:
- Frequent IP blocks and CAPTCHAs
- Region-locked content
- Steep learning curve for custom code and proxy rotation
- Legal confusion about public-data compliance
Mainstream solutions fall into two camps:
- API-centric tools (e.g., Apify Instagram Scraper, Bright Data Followers API)
- Require JSON inputs, proxy management, and post-processing scripts.
- Point-and-click “scraper” extensions
- Easy to start but break on complex sites, offer no scaling, and seldom handle geo-targeting.
Many teams end up juggling proxies, schedulers, and headless browsers—burning budget on dev hours rather than insights.
Two Serious Options: Apify vs BrowserAct
Feature | Apify Instagram Scraper | BrowserAct (no-code) |
Onboarding | JSON config or API call | Visual agent builder |
Coding required | Low (but still code/CLI for automation) | None |
Proxy handling | BYO or paid rotation | Free built-in geo proxy (country / city) |
Data scope | Posts, profiles, hashtags, places, comments | Any web page your agent can browse |
Real-time control | Logs only | Live browser—pause, type, solve CAPTCHA |
Pricing model | Pay-per-result (e.g., $1.50 / 1k) | Credit per run time (proxy included) |
Best use case | High-volume, repeatable APIs | Fast prototypes, non-dev teams, region-specific tasks |
TL;DR – If you need a REST endpoint for massive pipelines, Apify is great.
If you want to skip code, proxies, and CAPTCHAs entirely, BrowserAct is faster.
Quick Start Guides (Separate Workflows)
Apify Instagram Scraper (API Way)
- Sign up at Apify and open
apify/instagram-scraper. - Paste JSON input, e.g.json
{
"search": "Niagara Falls",
"searchType": "place",
"resultsType": "posts",
"resultsLimit": 100
}
- Choose a proxy group (optional) and Run.
- Download the dataset or hit it via
https://api.apify.com/v2/datasets/<id>/items.
BrowserAct (No-Code Way)
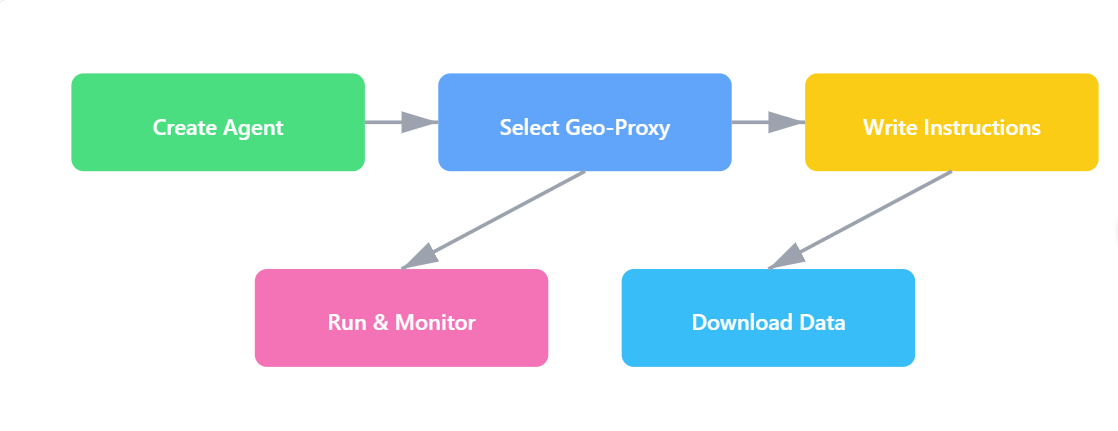
- Create an account → +Create Agent.
- Name it “Instagram-Scraper”, and make a description.
- In Proxy, select the target Country / City—free.

- Write natural-language instructions for this agent
Visit https://www.instagram.com/explore/tags/mealprep.
Scroll until you load 50 posts.
Click each post → capture caption, likes, first 20 comments.
Save results to CSV.
5. Click build. give it a task in conversation. Watch the live browser; step in if a CAPTCHA appears.
6. Download the CSV in "Output"
Why I Ultimately Recommend BrowserAct
- Zero code, zero proxy fees – Marketing or research teams launch scrapers in minutes.
- Geo-targeted data out-of-the-box – Essential when hashtags trend differently by country.
- Human-in-the-loop – Pause and guide the agent through log-ins or unexpected pop-ups.
- Faster iteration – Change instructions on the fly; no redeployments.
“I built a working Instagram sentiment collector during lunch—no Python, no proxies.”
— Actual BrowserAct beta user
Common Questions & Fixes
Problem | Apify Path | BrowserAct Path |
Only 5–7 comments scraped | Increase results Limit & add proxies | Switch proxy region; scroll manually if needed |
Need posts before a date | Filter timestamp field post-download | Add “stop when date < 2024-01-01” to instructions |
Download images/videos | Use displayResourceUrls array | Add “right-click → save as” step in agent |
Scrape a private account | Impossible—respect Instagram TOS | Same; BrowserAct limits to public data |
Content for a specific country hashtag | Buy geo proxies | Select the country in Proxy dropdown |
Cost & Compliance Snapshot
- Apify – $2.30/1 k comments; starter plan $49/month (~21 k comments).
- BrowserAct – Free proxy; pay only for agent run-time credits (visible before each run).
- Both tools fetch only public data and comply with GDPR/CCPA when used responsibly.
Choose Your Scraper
If you… | Go with |
Need a scalable REST API for large pipelines | Apify Instagram Scraper |
Prefer drag-and-drop setup, live control, free geo proxies | BrowserAct |
Ready to Try?
- Explore Apify’s actor: Instagram Scraper
- Build your first no-code agent: BrowserAct Free Launch 😊
Happy scraping—and may your IPs stay unblocked!

Relative Resources

Get free user reviews on Expedia without buying a search interface!

Ecommerce Dynamic Pricing Monitoring Guide

How To Scrape LinkedIn Without Code Using BrowserAct (No More APIs or Python!)

What Is Document Workflow Automation And How It Works
Latest Resources

What Are Claude Skills? Build Browser Automation Skills That Actually Work

Top 10 Claude Skills for Researchers in 2026: A Data-Driven Ranking

Top 10 Claude Skills for Web Scraping in 2026: A Data-Driven Ranking
